Storage Architecture Roundup (Part 1): What's Old, What's New, What's Nonsense.
Food for Thought
While at VMworld last week, besides booth duty, I had some time to stop and visit other vendor booths. It has always been one of my favorite things to do at VMworld- you get to see how the big boys are positioning themselves and what exciting new startups are ready to change the world.
I also was able to sneak into two sessions. The first was the always awesome Bruce Davie and his NET5716 - Advanced VMware NSX Architecture session. I highly recommend watching the recording if you missed it. The second was Chad's STO5420–SDS session, and one slide he put up really resonated with me, talking about the 3 types of storage architectures. The only change I would make is split the second type into two different ones.
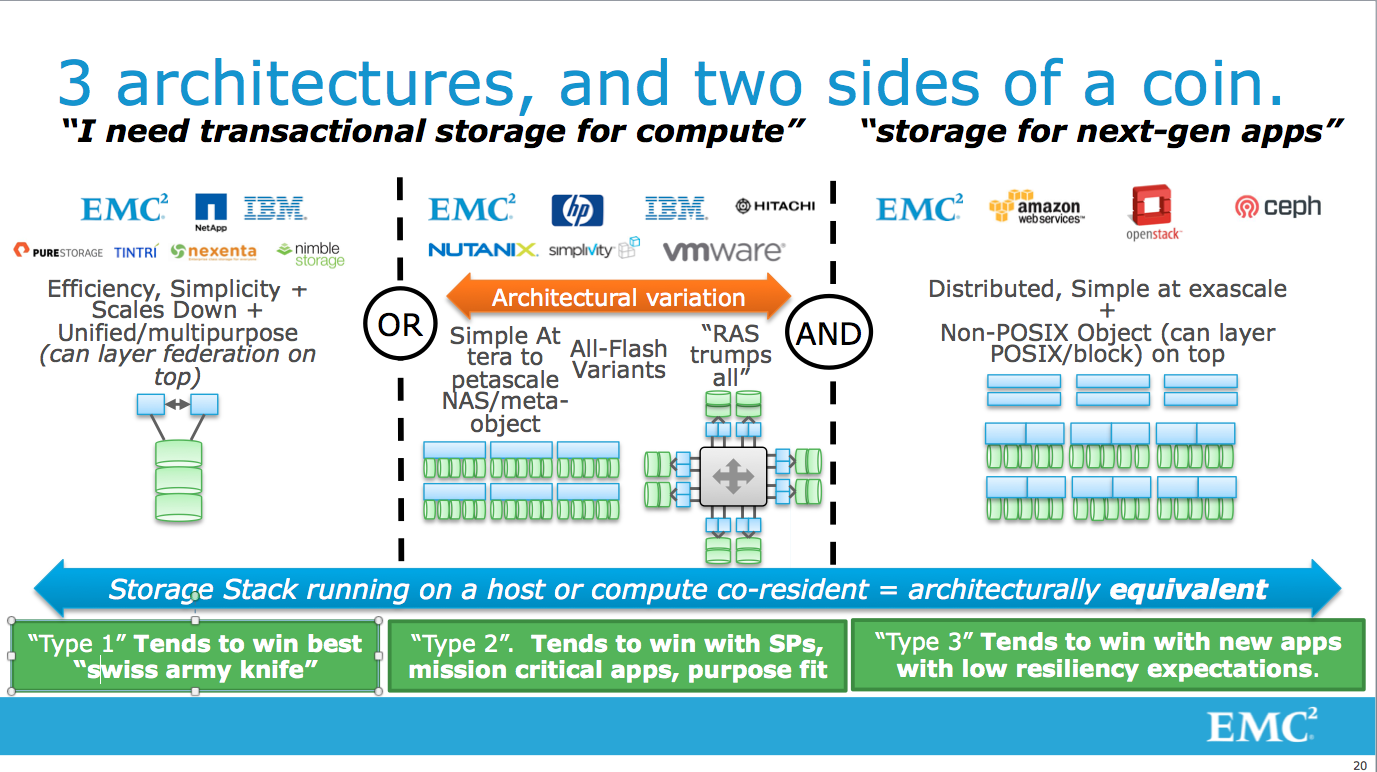
This really got me thinking. Can we really put all the currently available architectures into one of these four buckets? It really crystallized as I talked to smaller/newer vendors with "new" architectures as they (as most vendors do) highlighted the strengths of their approach and ignored/dismissed the caveats. Chad was right. Almost every single offering, new and old, fit into one of these models. Trying to claim your new product is some incredible paradigm-shifter that doesn't fit into these buckets? Most likely nonsense.
In this 3 part series, we'll talk about each of the models, some examples of them, what the engineering trade-offs are that are being made, and what it means for the types of workloads these architectures can handle.
The Four Storage Architectures
In Chad's slide above, he names three types. First off, I'm going to set aside Type 3 (Object storage), and focus on the transactional storage models:
Scale Up (Type 1)- These are your traditional-style dual controller arrays. Scale by adding disks. Think: EMC VNX, NetApp, Pure , Nimble, Compellent, IBM DS8000.
As I mentioned, I'm going to split Type 2 into two separate models:
Scale Out (Type 2a)- This is your modern shared-nothing architecture. Scale by adding nodes, each with processing and storage. Think: EMC Isilon, Nutanix, ScaleIO, IBM XIV, VMware VSAN.
Scale Around (Type 2b)- This is an older architecture model, but is in use by a couple of younger platforms as well. Scale around is a scale-out architecture that is purposely limited to a finite maximum. Scale is primarily an availability operation instead of a performance one. Scale by adding disks & nodes. Think: EMC VMAX, HP 3Par, HDS VSP.
To avoid a War & Peace blog post, I'm going to hit on a two consistent themes and then dedicate a post to each of the above types.
The Latency Compass

When measuring a system for performance the only important measurement of latency is cumulative latency. The client asks for an IO- how long does it take to return with the data or acknowledgement for the write? That said, when designing a system you need to measure the latency at all the relevant points to be able to minimize it as much as possible.
Designers of High Performance Computing (HPC) clusters refer to two types of latency: East-West latency and North-South latency. East-West is inter-node latency. If your process or job has to talk to other nodes, it's the amount of time it takes to complete that part of the IO. North-South latency is client/node latency. How long from the request at the client until it gets a result from the requesting node.
Why are we talking about this here? While storage latency had been defined for years by mainly N/S latency with negligible E/W latency, some of these newer architectures flip this on its head. We'll discuss how it effects each architecture.
Do Work Son!
 One last note on storage arrays- array controllers (software or hardware) are busy beavers. The amount of operations that must be done per client IO have only increased from things like just RAID calculations to now include hashing for dedupe, compression, RAIN ops, replication, snapshots, etc etc. So not only are modern storage systems doing more client IOPS overall, they're doing more work to complete each of those IOs.
One last note on storage arrays- array controllers (software or hardware) are busy beavers. The amount of operations that must be done per client IO have only increased from things like just RAID calculations to now include hashing for dedupe, compression, RAIN ops, replication, snapshots, etc etc. So not only are modern storage systems doing more client IOPS overall, they're doing more work to complete each of those IOs.
Luckily, most array vendors have switched to x86 architecture and Moore's Law (and our friends at Intel) has provided leaps in CPU horsepower to handle the additional workload. That said, it's still far from a negligible workload and if you're looking to leverage software or virtual arrays, you will need to add additional (sometimes pretty significant) compute power to handle that workload.
Next:
Storage Architecture Roundup(Part 2): Type 1 Storage- Scale Up
Storage Architecture Roundup(Part 3): Type 2a Storage- Scale Out
Storage Architecture Roundup(Part 4): Type 2b Storage- Scale Around & Conclusions