What's in it for me?
Think about how many times you’ve complained about another function at work:
- Human resources making it harder to hire/fire/promote someone
- Simple licenses or contracts caught up in Legal for months on end
- Information Security bogging down your project with extra work
It goes on and on. The same thing happens outside of work too. The best examples are usually in the public sector. It seems like some people almost enjoy making your life harder, doesn’t it?
They’re not Evil
People automatically assume that these lines of work automatically attract sadists or something. You’ll hear people vent about so-and-so being on a “power trip.” While there are people who are like this, they’re actually few and far between. What you need to do to understand what’s happening is to try to have some empathy and put yourself in their shoes for a moment.
You’re now in the legal department of a large multinational software company. You get requests daily to review licenses and contract terms. If you let something through that later is a problem, you take the blame for it. If you let something through that isn’t a problem and actually helps get a product out faster, you don’t get any of the credit.
Risk vs Reward
Life (and business) is a constant juggle of risks versus rewards. Is the risk of x worth taking in exchange for y reward? Do I pay extra for comprehensive insurance on my used car? Do I ask out that man/woman that I see at the coffee shop every day? Do I approve this contract with the terms as is?
The problem for these people and departments we’ve written off as wet blankets that are only there to make things harder is a lack of reward. If an HR person approves a nonstandard offer get a specific engineer onboard do they see any of the credit when the product is better or ships faster? No, they only see the risk of the downside—potential problems with other current and future employees compensation.
Risk Minimization
Since there’s no upside, they’re really not managing risk, they’re minimizing risk. If there’s anything that will increase the risk, the answer is no, no matter how high the reward. The only exception is when someone else (generally an executive) is willing to sign off on the exception so now the potential blame is transferred to them.
Bad Incentives, Bad Leadership
This is all rational human behavior—You would do the same in those positions. The problem is clearly a bad system of incentives. They’re only exposed to negative incentives, so they only react to those. It’s not their fault, it’s a failure of leadership. Your company’s leadership needs to put people in the right positions and armed with the right incentives to make the decisions that are best for their team and the company as a whole.
Adversaries at Work
If this is so obvious, why are so many relationships set up this way? The adversarial system is a legal construct that has been used in common law countries for centuries. Somehow in the US it got folded into the competitive aspect of capitalism leaving us with the “common sense” idea that it gives us the best outcomes. Labor negotiations are a great example of this- the company and the union in diametrically opposed positions will move to an equilibrium that’s the best for both sides. As we’ve seen over decades, this is often not the case and why more collaborative labor negotiation setups like in Germany have lead to better outcomes for the company and the employees.
We’re practicing this same approach in these relationships at work. The infosec engineer’s job is to represent the side of security, and the developer is representing the side of usability and therefore revenue. The idea is where they choose to compromise will be at the best risk/reward point. As we’ve seen many, many times this breaks down here too.
How do we fix this?
This is clearly a complex situation that has no easy silver bullet fix. Leaders need to constantly be evaluating all of the incentives—positive and negative, direct and indirect, to make sure they’re aligning with the company’s overall goals. How can legal share in the reward when the product ships sooner and how can the product teams share in the downside when there’s a licensing or security issue?
Team Up
One of the easiest options that can work well in certain environments is to move these roles into the teams that they’re supporting. Instead of an infosec department, why doesn’t the product team have one or two infosec trained engineers on their team with them? They’re now part of the team that’s rewarded when the product succeeds, and the entire team is exposed to the risk of a security problem because it’s not “someone else’s problem.” We’re starting to see DevOps teams transform into DevSecOps teams for this exact reason.
A great example of this that I’ve gotten to witness personally at IBM/Blue Box was having the recruiter responsible (the incomparable Jill Jubinski) for hiring into the team be a part of the team. Having a recruiter know what your teams do on the day to day basis is really powerful. They will understand individual team micro cultures and be involved in planning—making them a strategic partner. They’ll know when you’ll need people before you do. Also, it gives the recruiter the ability to always be recruiting—if they know your team and find the ‘perfect’ candidate they can push to open headcount.
These are just a few examples of how leaders can break their organization out of this dysfunctional dynamic and get their teams working in a more productive manner with the same goal in mind.
Deploying Spring Boot Applications on IBM Bluemix
If you’re not a Java developer (neither am I), you might not know about some of the newer technologies that are starting to get popular. These tools are all about getting java applications built and running faster. The focus is on lightweight application servers that boot quickly and have a simple configuration that only builds runtimes with the essential components. For example, the latest version of IBM WebSphere, called Liberty is designed in this manner with a footprint under 60MB and boot times under 2 seconds.
Spring Boot
Another very popular example comes from Spring.io called Spring Boot. For people already using the Spring framework, Spring Boot is a great way to quickly get an app up and running. These type of tools are a change from previous java application development and deployment methodologies. Steve Perkins has a good post explaining the advantages of Spring Boot Here.
Spring Boot on Bluemix
One of the great things about Bluemix is developers have tons of options for how they want to build and deploy their applications. If you like docker, and want to deploy your spring boot app to Bluemix with a docker container, a fellow IBMer did a great post on it here.
What if you would rather deploy your Spring Boot application on Cloud Foundry? Let’s do this!
- First, make sure you have the Cloud Foundry CLI installed and the build manager of your choice (I’m using maven).
- Next, let’s get a copy of the Spring Boot repo with the sample apps.
``` git clone https://github.com/spring-projects/spring-boot.git
* Now, we need to pick a sample app- let's use the web-ui sample.
``` cd spring-boot/spring-boot-samples/spring-boot-sample-web-ui
- We need to build the app so we can have it ready to deploy.
``` mvn package
* Once it's done we have a JAR that we can deploy to Cloud Foundry. We'll use the '-p' flag to specify the JAR we just created.
``` cf push tbspring -p target/spring-boot-sample-web-ui-1.3.1.BUILD-SNAPSHOT.jar
In this case we didn’t supply a buildpack so Cloud Foundry used the default java buildpack. For Bluemix, this is the Liberty for Java buildpack. What if we don’t like that? What if we want to use the community java buildpack? It’s just as easy as using the ‘-b’ flag and supplying the url to the buildpack:
cf push tbspring -p target/spring-boot-sample-web-ui-1.3.1.BUILD-SNAPSHOT.jar -b https://github.com/cloudfoundry/java-buildpack.git
When it’s done, we have a running Spring Boot app on Bluemix Cloud Foundry. Pretty easy.
Cloud Encryption is Fool's Gold
I constantly see a number of encryption vendors selling their wares by promising to ‘protect your VMs in the cloud’ or ‘help you meet PCI compliance in the cloud’ through encryption. What these vendors are selling is a technology called Data at Rest Encryption (DARE). It’s a style of encryption that leverages either existing OS-level encryption or deploys its own encryption agent but generally lives right above the storage drivers in the operating system. In this use case, it runs inside the VM and encrypts data as it is written and decrypts it as it is read. Some even leverage underlying hardware acceleration if it’s available.
DARE? How Does it Work
Data at Rest Encryption is an important technology that’s been around for some time. How it works is pretty straightforward. A software module, either provided by the OS or the software vendor, is loaded into the I/O stack and intercepts all traffic between the rest of the server and the underlying disk. It encrypts disk blocks as they are written and decrypts them as they are read. To the rest of the server, applications, and users this process is seamless and goes unnoticed. It’s called ‘at rest’ encryption because the only place where the data is encrypted is the data ‘resting’ on the disk.
What About Keys?
The one thing I haven’t mentioned yet is encryption keys. That software module that’s doing the encryption work needs a key to encrypt and decrypt the data. Depending on the implementation, it gets those keys in a different way. A common way is to encrypt the key using a password. This is a common way FileVault on OS X works. When my laptop boots, the UEFI boot loader asks for my password which it uses to decrypt my encryption key and pass it to FileVault which uses that key to mount my encrypted hard drive and boot my system. My key is stored in memory by FileVault, but when my laptop is powered off, the memory is cleared.
While that’s fine for one machine, it generally doesn’t scale. So many vendors offer some sort of centralized key manager that a server needs to check in with to get its key. This central server can also perform other management tasks like changing keys, pushing agent upgrades, etc. Just like my FileVault example, when the machine is powered off or rebooted it needs to check in with the key manager to get a key otherwise it can’t decrypt the data.
What’s the Problem?
Sounds great, right? Honestly, it was and still is great for physical use cases. For example, disposing of failed disks is easier because you don’t have to worry about sensitive data on it. Everyone with even the slightest bit of sensitive data (tax returns?) on your laptop should have a password and encryption turned on. If you lose your powered off laptop or it’s stolen, your data is safe (unless you have your password on a sticky note on your laptop).
Notice how I said ‘powered off.’ As long as your laptop is running, the process doing to encryption work is running and has the key in memory. How do you get to the key as an attacker? It’s really hard- you need to access the memory chips and siphon the keys out. I’m sure the NSA & CIA has equipment to do this, but not your average thief. There’s an old security maxim that if someone has physical access, you have to assume they’ll eventually be able to gain full access. In this case, it’s still a pretty rare combination.
One Click Access
Still don’t see a problem yet, right? Well here it is: virtualization and cloud technology makes it much, much easier to access both the storage and the memory of a running machine. What used to take a CIA-level capability, can now be done by almost any server admin. If you’re running a VM somewhere, whoever administers the underlying hypervisor has access to your data, encrypted or not.
How? Well Since the hypervisor stands between your VM and the hardware, it adds some great new capabilities (live migrating servers, moving storage, resizing VMs while they’re running, etc). It also includes the ability to dump the memory of a running VM to a file without the VM knowing. I can also copy the storage your VM is using without you knowing.
If you’re leveraging something like BitLocker in a VMware vSphere-backed environment to do the encryption, defeating it as an admin is stupidly easy:
- From the GUI, take a VM snapshot, and check the box to include the memory as well
- download one of the many BitLocker decrypter programs
- point it at the dumped memory as the key location and the vmdk as the encrypted data
- mount the unencrypted data to the windows machine of your choosing and you now have all the data.
It’s that easy and the owner of the VM is none the wiser.
Turtles All the Way Down
This is the part where vendors that do things differently generally jump up and go “ah ha! we’ve thought of that and we’ve overcome that problem!” This usually applies to solutions that do centralized key management. Their main defense is some sort of nested key arrangement- the key server doesn’t give out the key to the data, it gives out the key to unlock the key for the data. This approach has some advantages- it allows re-keying a machine without having to decrypt and re-encrypt all the data to change keys. The problem is, even if they decrypted the data key on each actual use every millisecond (which would kill performance), the outer key (the one decrypting the data key) is still stored in the clear in memory. Why don’t they encrypt that key? You can keep going down the line, but sooner or later the outermost key has to be stored in the clear in memory for any of this to work. So when I take a snapshot of a VM disk and its ram, there’s a key in there that can get me to the data in the memory, period.
One other defense mechanism that is trotted out is they assume the person trying to steal the data is going to power the cloned/snapshotted VM on. Their agent will contact the key server, and the key server will either not supply a key, or in the case of nested keys, tell the agent to destroy the encrypted data key. While this is generally a good feature to have, it still doesn’t fix any variation of scenario we talked about above. Not to mention if your VM is compromised while it’s running, it’s totally unnoticeable to the attacker just like any other person or app accessing the data on the server.
Meeting Compliance
Many security and encryption folks will usually drop back to “yeah, well, that all may be true, but we’re required to encrypt to meet some compliance requirement and this checks the box.” From my experience, this is usually incorrect and due to a misreading or misinterpretation of the relevant policies or governing documentation. A perfect example is people encrypting VMs on Amazon Web Services to “meet PCI compliance.” A quick google search will uncover that the entire AWS platform has received PCI DSS Level 1 certification. Now that doesn’t absolve those handling payment data from any other responsibilities in regards to PCI DSS, but there’s no need to encrypt VMs there to “meet PCI compliance.” I’ve seen this throughout my career both as a customer and as a consultant, each company interprets regulations and policies differently. It’s not surprising because most of the regulations are purposely vague and focus on outcomes not techniques. There are obvious exceptions that are very prescriptive, but that’s not the norm.
Conclusion
Clearly DARE is a good technology for protecting physical computers with minimal impact on the user experience. We should all embrace any technology which is that straightforward. The problem is trying to apply this technology to virtual and cloud environments. So if doing DARE in the cloud doesn’t protect your data from a cloud administrator or from someone who has compromised your VM, what is it good for? Filling vendor bank accounts.
Cloud Disruption or Failed Leadership?
Watch enough presentations on modern IT and cloud computing and you’ll see the same theme over and over. New companies that are Digital/Platform 3/Cloud are disrupting existing industries. The most well-worn examples are Uber, Tesla, and Nest. The takeaway of the presentation is supposed to be that this huge technology advancement is enabling smaller companies to disrupt larger established players and if you want to disrupt/avoid being disrupted, you must embrace these new technologies.
How to Survive?
Along with the tales of this massive technology disruption to not only IT but businesses as a whole, a frequently cited strategy for overcoming it is ‘Bimodal IT.’ The premise which is espoused by Gartner, IDC, as well as a number of vendors basically describes an IT department divided into two groups— a group focused on existing ‘legacy’ IT while a new group needs to be created to design-build-run these new ‘cloud-native apps.’ Not only is this concept built on an incorrect understanding of the forces at work, actually trying to implement it is a recipe for disaster.
Revolution or Evolution?
As new ideas or products are invented, they start out hard to define hard to predict entities that evolve over time. The more share they gain, the more defined they become.
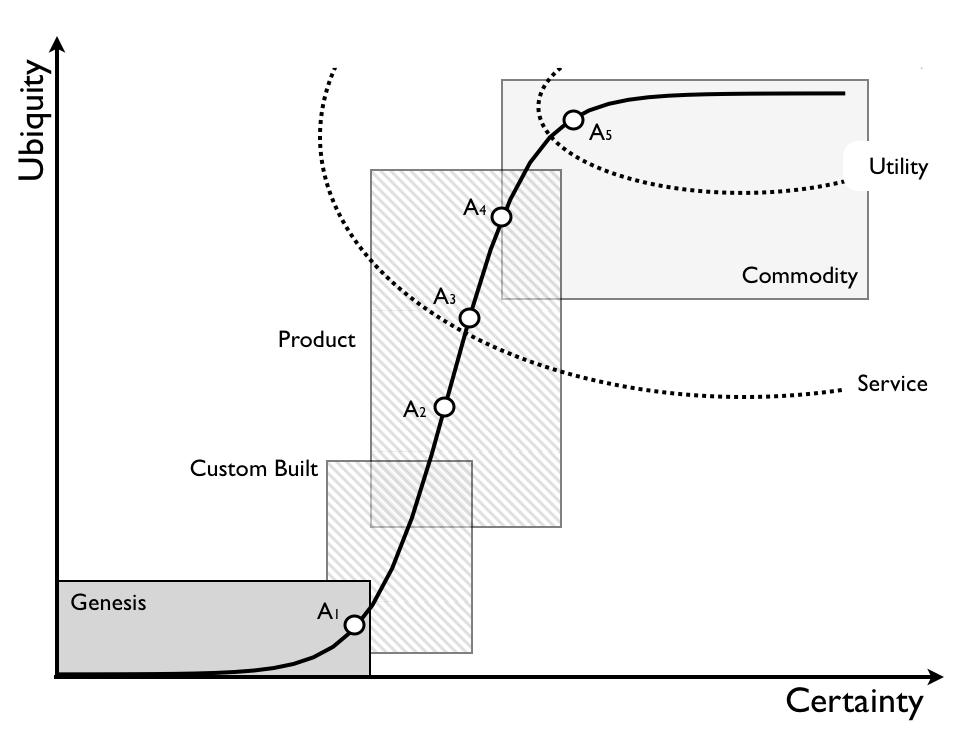 Simon Wardley has covered this extensively on his blog and in many talks. It’s the march towards ubiquity and utility.
Simon Wardley has covered this extensively on his blog and in many talks. It’s the march towards ubiquity and utility.
From the perspective of computing, what are we really seeing happen here over the past decade? It’s compute moving from being a product that you buy (servers), into services you consume, to a utility that you pay that’s metered in hours and minutes. It’s a normal technology evolution which was neither unpredicted (John McCarthy foretold of utility computing in 1961!) nor a dramatic technology advancement to the consumer.
The Next Age of Compute
If this is a expected normal evolution of computing technology, why are so many companies struggling with it? Cloud computing has brought along another change with it that’s really causing the disruption.
Since VAXcluster was released by DEC in 1984, we’ve been living as an industry in the age of clustered systems. The learning curve in the early days was high and required the best and brightest. As clustered systems became more understood and productized, it was easy to understand and move from things like Microsoft Cluster Services to VMware DRS/HA Clustering. Developers built apps that expected and understood clustering technologies ‘just talk to the database at this IP’ and infrastructure engineers knew how to build and maintain them.
Cloud computing marks the arrival of the age of distributed systems. It requires significantly advanced skills to both build apps and infrastructure that operate in this manner.
Skills Shortages are the True Source of the Disruption
Ask any hiring manager working on distributed systems on either the development or infrastructure side and they’ll tell you how few candidates there are with the skill sets they need. How did this happen?
Years of Bad IT Leadership
Let’s go back to that chart we started with. How many CIOs in the previous decade put a dot on there called ‘IT’ and decided it had been pretty much all commoditized, so why not outsource all of it to IBM Global Services or EDS? Or even if they had enough sense to break that dot apart, it was probably only into two dots called ‘development’ and ‘infrastructure’, they probably still put these two monoliths near the top right. What did they do then? Offshoring, replacing ‘expensive’ experienced developers, architects and engineers with less experienced, cheaper ones. Now that they need developers and engineers with higher skill levels, they’re nowhere to be found.
Hiring: Must have 10 years Docker Experience
It’s amazing to see IT and HR organizations that can’t understand why they can’t find people with tons of experience in a brand new technology for their set developer/engineer rates, either internally or externally. They’ve completely forgotten that:
- They’ve been using offshoring, H-1B visas, and other cost saving measures that have suppressed their pay rates on common technologies and think that applies broadly
- They only pay lip service to personal development and skimp on training and conference attendance budgets.
- They’ve become so focused on process for process’s sake (ITIL, etc.) that anyone they had that could have picked up this new technology quickly is long gone.
And at the same time, a few of their similar sized competitors have had no trouble taking advantage of cloud computing, barely missing a beat. The organizations that are surviving and thriving have a common thread— their teams have discovered and learned these new technologies on their own, they weren’t hired in.
The organizational structure, leadership, inertia, and internal development (or lack thereof) is what’s causing disruption not ‘The Cloud.’
Why Bimodal IT Isn’t a Cure
This is why bimodal IT is so nonsensical. Assuming if you decided to split your IT shop into two groups:
- Where are you going to find the skills you need?
- Who is going to want to stay in the old organization with the implied scarlet letter of ‘you’re not as good as those people we chose’?
- 10 years from now when there is the next new age, do you create a third group? New, Less New, Old? Does the ‘old stuff’ get handed off to the group that stayed behind? Does the new group become the old group and the old group is fed to lions?
If it is so nonsensical, why is it gaining favor so much? It’s because so many companies want it to be true. Bimodal tells them ‘all the decisions you made up to now were right, and you don’t have to make drastic changes, just add a new team to address these new needs.’ It provides them with the smallest disruption to their current worldview. Simon has a great post on Bimodal here, including alternatives.
An IT Wakeup Call
The relatively slow pace of enterprise technology changes over the past decade lulled IT leadership into thinking that this was the norm. Why bother investing in your employees and advancing their skill sets when they could pick incremental new technology in their free time? IT departments were seen as a cost center that had to be controlled and the services IT provided mature and well understood.
It turns out this simple, myopic view of IT and the decisions made based on that view are what’s really causing the disruption in Enterprise IT today— not cloud computing.