Storage Architecture Roundup(Part 3): Type 2a Storage- Scale Out
If you landed on this post, you may want to start with Storage Architecture Roundup (Part 1) and Storage Architecture Roundup (Part 2): Type 1 Storage- Scale Up.
Type 2a: Scale Out Storage
Architecturally, this sounds like the most simple, but is by far the most complicated. The basic make-up varies much more with type 2a systems- it can be packaged as a complete storage array like Isilon, a software-only offering like VMware VSAN and EMC ScaleIO, or an all-in-one storage & compute offering like SimpliVity or Nutanix.
Client IO Path
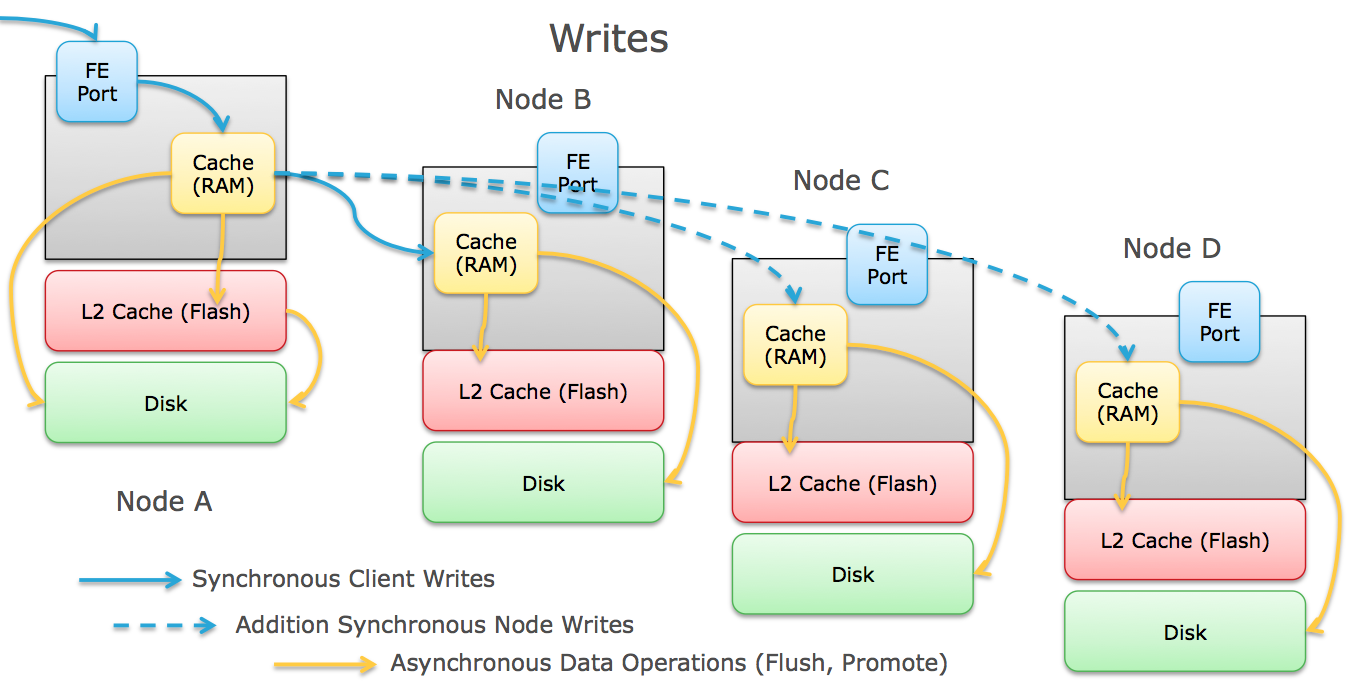
The Flow of write IOs through a scale out array can vary depending on the architecture, but generally goes like this:
- The client initiate an IO and transmits it to the node it's communicating with. For all-in-one style architectures, this is a VM node that's co-located with the client on the same hardware.
- The node receives that IO and caches it into memory (generally RAM, sometimes SSD).
- For data protection purposes, the node also transmits the IO across an inter-node link (usually Ethernet, sometimes Infiniband) to the other node(s) which caches the IO into its memory as well, and acknowledges that write back to the first node. Depending on the architecture, this could be one other node, or every node in the cluster. Also depending on the architecture and protection scheme, the node may break the write up into smaller pieces before distributing them to the other nodes.
- Once the node receives the write acknowledgement from the other node(s), it responds back to the client acknowledging the write.
- Depending on the array platform, other things can be done with the write like inline deduplication, compression,etc.
- Some arrays that implement flash-based write caching can stage the writes to flash to clear the RAM for more incoming writes.
- The write is eventually flushed to disk (SSD or Magnetic) on each node that received the write.
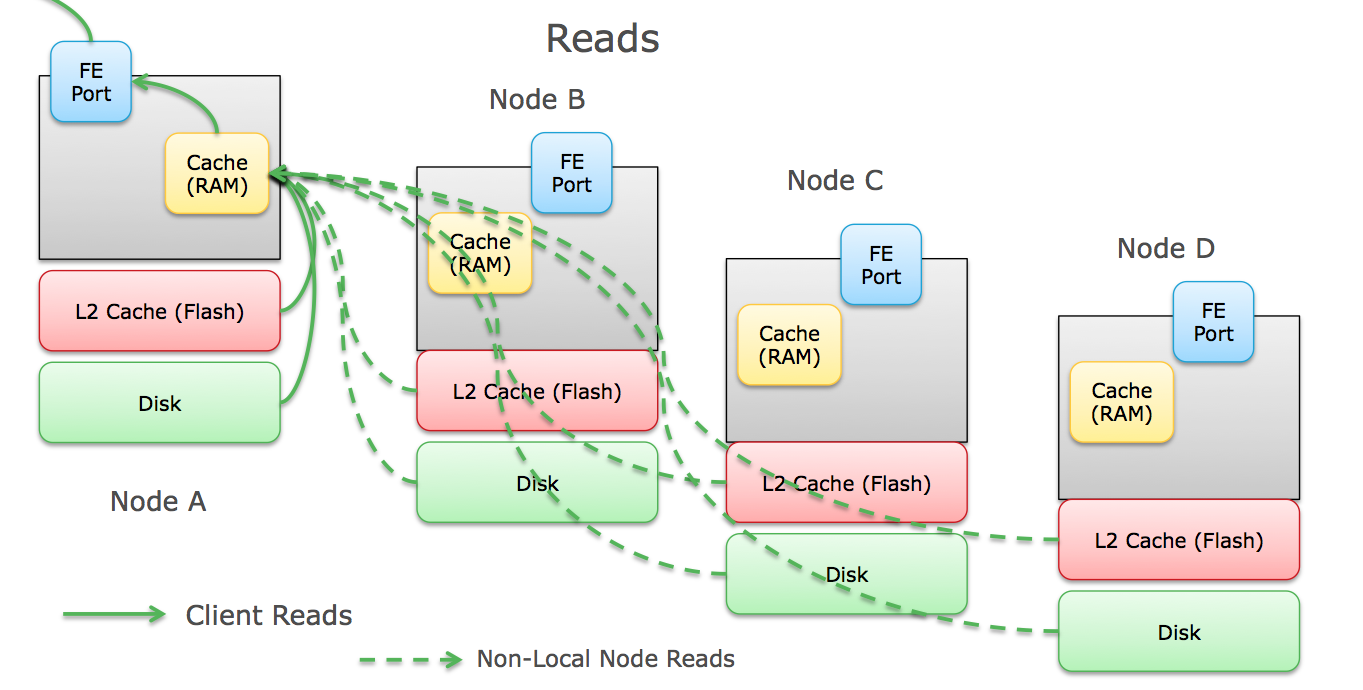
The flow of read IOs is less complicated:
- The client initiates an IO request and transmits it to the node its communicating with. For all-in-one style architectures, this is a VM node that's co-located with the client on the same hardware.
- The node receives that IO, checks its read cache in RAM for the data and then (depending on the array) checks SSD cache for the data.
- If the data isn't in either location, it's a " read miss" and the node checks its metadata table to see where the data resides on disk (local or another node or nodes). Data is read directly from the underlying disks if it's local or it is requested from containing node across the inter-node link, and wait for that data to return.
- The node places a copy of the read in cache (if it was a "read miss") and responds to the client with the requested data.
Characteristics of Scale Out Arrays
Positives
- Client/Node latency (North/South) is so low (<1ms) on all-in-one solutions, it is completely negligible. Almost all total latency felt by the client is caused by East/West latency.
- Performance generally scales with nodes- more nodes mean more CPU, RAM, Disk. Many of the architectures have node count limits, but are theoretically can have unlimited nodes.
- Inter-node latency (East/West) can be high, dramatically increasing write latency and random read latency. This is why many architectures (particularly server-virtualization specific ones) leverage some sort of localized read caching to minimize traversal of the inter-node link.
- Since E/W latency can be high, these architectures are fantastic at large sequential read workloads, as the effects of inter-node latency can further be minimized by read-ahead algorithms and caching, effectively parallelizing the workload across nodes.
- These architectures generally don't use specialized hardware designs and leverage low-cost server-style platforms.
- They generally create large pools of storage (mostly file-based) which can require less administration (one 2PB pool vs two thousand 1TB pools)
Negatives
- Scale is generally not exactly linear- much like CPU core scaling, more nodes mean more inter-node coordination which offsets a percentage of the resources of each new node.
- As many of the architectures are software-centric running on COTS hardware, their hardware fault detection/isolation capabilities are nonexistent. The general response to a misbehaving node is to fail the entire node. Failure rates versus specialized hardware is generally higher.
- There is a protection/performance trade-off these architectures have to make- either break your data into pieces with parity/hashes which lower storage capacity requirements but decrease random performance, or make multiple copies of your data which is faster to read/write with less performance overhead, but requires significantly more storage. Think RAID5/6 vs RAID10.
- To create those simple to manage pools on the front-end, there is a lot of engineering magic going on in the back-end. This complex back-end can make performance and other troubleshooting much more difficult.
- While the storage may scale-out, some apps can't properly take advantage of all the nodes for access which can lead to hot nodes.
Failure Domains
- Almost all failures in a scale out system are handled at the node level- any issue with a node, and the entire node is marked as bad.
- Some Architectures like SimpliVity and Isilon also do local RAID on the nodes and can handle an individual disk failure without failing the entire node.
Some Examples
- Scale Out Hardware- EMC Isilon, Dell Equallogic, HP StoreVirtual 4000
- Scale Out Software- VMware VSAN, IBM SONAS, HP StoreVirtual VSA, EMC ScaleIO, VMware Virsto
- All-In-One- SimpliVity, Nutanix
DAS (Direct Attached Storage) is Fast!
This is a common argument I'm hearing lately for these architectures, especially the software or all-in-one versions that run co-located on the same hardware as virtual machines. While technically correct (DAS can be incredibly fast- look at performance numbers on PCIe Flash like XtremSF), these solutions aren't DAS. There is a layer of abstraction (the software architecture we're discussing above) that provides tons of value, but also adds latency. If you don't care about the protection of the data (Non-persistent VDI, data warehouses, etc.), running on DAS is a great idea- if you run directly on the storage (DAS!) without any of this in between. Mark Twomey goes more into detail on his blog.