Storage Architecture Roundup(Part 4): Type 2b Storage- Scale Around & Conclusions
If you landed on this post, you may want to start with Storage Architecture Roundup (Part 1), Storage Architecture Roundup (Part 2): Type 1 Storage- Scale Up, and Storage Architecture Roundup(Part 3): Type 2a Storage- Scale Out.
Type 2b: Scale Around Storage
So to be clear, this is not an accepted industry term. In fact, by googling "Scale Around Storage" it appears no one is using this terminology. So why am I using it here? The more standard terminology for this class of arrays would be the same as type 2a- Scale Out. While it is accurate, these arrays have a significantly different architecture and design considerations that make them different enough from the scale-out systems we already talked about to warrant their own category.
What about Monolithic, Enterprise, or Mainframe class?
Yes, some of these arrays have previously been called those names, but there are others (like the IBM DS8000) that has been called all three of those things, but is architecturally a type 1 dual controller array.
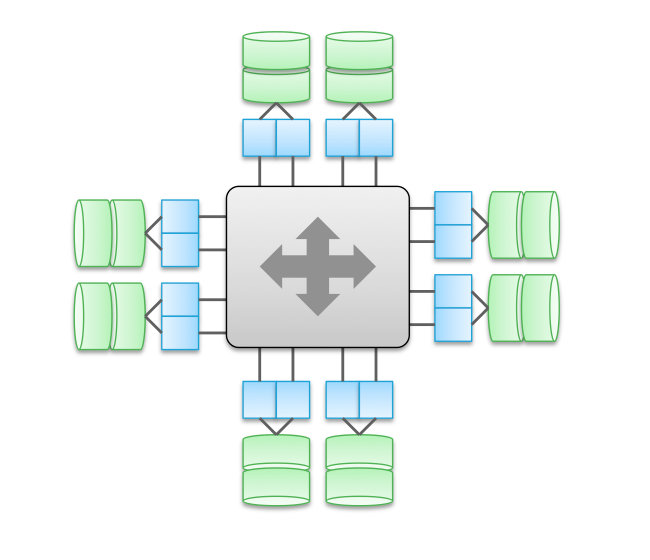
Client IO Path
You'll notice the diagrams are similar to the ones from Type 1. The two main differences in the diagrams are:
- The two controllers displayed can be two of many more controllers (up to 16 on the VMAX).
- Inter-controller communications in Type 2b can actually bypass the CPU of the remote controller for higher performance.
The Flow of write IOs through a scale around array can vary somewhat, but as an example IO through a VMAX generally goes like this:
- Client initiates the IO and transmits it across the network (SAN or IP SAN) to the next hop.
- The IO flows through all the switch hops and lands on the front end port of one of the controllers.
- The controller receives that IO and caches it into global memory in two locations on two different controllers. It access the memory locations directly via the inter-controller link (RapidIO).
- Once the controller confirms both writes have been made, it responds back to the client acknowledging the write.
- The write is eventually flushed to disk (SSD or Magnetic).

The flow of read IOs is similar:
- Client initiates the IO request and transmits it across the network (SAN or IP SAN) to the next hop.
- The request flows through all the switch hops and lands on the front end port of one of the controllers.
- The controller receives the IO request, checks global memory for the location of the data. If it exists in RAM, it will access the memory location directly via the inter-controller link (RapidIO) no matter which controller physically contains the data.
- If the data isn't in global memory, it's a "read miss" and the data is read directly from the underlying disks (flash or magnetic).
- The controller places a copy of the read in cache (if it was a "read miss") and responds to the client with the requested data.
Characteristics of Scale Around Arrays
Positives
- Inter-controller latency (East/West) is extremely low to the point of being almost negligible.
- Up to the maximum performance of the controllers, North/South Latency is dependent mainly on the back-end disks.
- Since both N/S and E/W system latency is so low, scale around arrays are great for transactional workloads that max out lower than the system's maximum utilization (<1ms response times possible, read and write)
- By limiting the maximum scale and hardware components, these arrays can deliver great transactional performance and at the same time unmatched reliability in comparison to type 1 and 2a arrays.
Negatives
- Scale is limited to the horsepower of the maximum number of controllers (For VMAX, it's 16). Most top out at around 2000-3000 drives.
- While some of these systems use x86 architectures, they are delivered in custom hardware packaging. The others use custom ASICs/hardware. This generally causes longer lead times for new technology (CPUs, chipsets) to make it into these arrays.
Failure Domains
- This is where Type 2b arrays really can shine. The microcode on these arrays can generally allow individual component failures (memory boards, ports, CPU cores, etc.) without having to take the entire controller offline. This resiliency provides higher availability as well as better performance during a fault. This is one of the main reasons customers choose this style of array.
Some Examples
- EMC Symmetrix VMAX
- HDS VSP
- HP 3Par
Conclusion
As you may have noticed, I have not called out one architecture as 'the best.' Like most things, there are engineering tradeoffs that are made, resulting in products that are better at some things than others. The real caution I can provide you is if some vendor tells you that they don't fit into any of these categories and they can do everything very well, they're either lying or uninformed themselves.